
目次
この記事の対象読者
Tensorflowを扱っていると、たまにこういうシチュエーションに出くわします。
「訓練データのサイズがでかいな…大部分がゼロだからどうにかしたいんだけど…」
「ん?調べてみたらSparseTensorってあるやん!これを使えば解決や!」
「あれ?TFRecords形式に保存するときは色々特殊なことしないといけないの?」
「おや、なんか良く分からんけどエラー出るな。。。解決策は。。。全部英語やないか(白目)」
はい、先日私がたどった思考です。SparseTensorを使おうとするとあちこちに罠が仕掛けられていて、TFRecords形式に保存するのも学習を回すのもなかなかうまくいきません。しかも、日本語の情報が皆無なうえに、英語の情報もリッチとは言えません。更に公式ドキュメントもなかなか分かりづらいです。
という訳で、SparseTensorについて調べてるとそれなりの情報量になりました。結構困ったので、同じ轍を踏む方が一人でも少なくなるように、とこの記事を書こうと思った次第です。本記事で解決する問題をまとめなおすと以下になります。
- SparseTensorの扱い方
- SparseTensorをTFRecords形式に保存する・そこから読み出す方法
- SparseTensorをモデルの入力として学習用のコードを動作させる方法
上記の問題を抱えている人にとっては有益な内容となっていると思いますので、最後までお読みいただけると嬉しいです。では本題に入っていきましょう!
なお、TFRecordsに関しては前回の記事が参考になると思いますので、気になる方はそちらも是非。

tf.sparse.SparseTensorの扱い方
まず、tensorflowでSparseTensorをどのように扱うかについて述べます。
SparseTensorは疎行列のテンソル版と捉えるとよいと思います。疎行列は要素のほとんどがゼロのときに、情報を圧縮して保存する際に登場します(最適化計算を高速化する際にも登場したりしますが、それはまた別の記事で)。疎行列の形式には
- CSR形式
- CSC形式
- COO形式
- LIL形式 etc…
など、何種類かの方式があります。SparseTensorはCOO形式で情報を保持します。つまり、2階のテンソル(≒行列)ならば、
- どの行に値が入っているか?
- どの列に値が入っているか?
- その値は何か?
の組み合わせを保持しているということです。例えば、4×4行列で、(2,3)成分に「1.1」、(3,4)成分に「2.2」という値が入っており、残りの成分がゼロというものを考えます。これはまさにCOO形式の考え方で、
- (2,3)成分 = 2行3列の位置に
- 1.1 という値
- (3,4)成分 = 3行4列の位置に
- 2.2 という値
が入っているという認識をしていることになります。つまり4×4 = 16個の成分を持つ行列を、[2,3,1.1]、[3,4,2.2]という6つの情報だけで表現していることになり、これが疎行列表現により情報が圧縮されるということの意味です。
さて、疎行列に関する前置きが長くなりましたが、具体的なコードでSparseTensorの扱い方について見てみましょう。実行環境について触れておくと、以下になります。
- OS:Windows10
- Pythonのバージョン:3.7.9
- tensorflowのバージョン:2.1.0
import tensorflow as tf
import numpy as np
# Sparse Tensor の情報
rows = [1, 2]
cols = [2, 3]
values = [1.1, 2.2]
shape = (4, 4)
# Sparse Tensor
sparse_tensor = tf.sparse.SparseTensor(indices=[rows, cols], values=values, dense_shape=shape)
print(sparse_tensor)
"""
【出力結果】
SparseTensor(
indices=tf.Tensor([[1 2]
[2 3]], shape=(2, 2), dtype=int64),
values=tf.Tensor([1.1 2.2], shape=(2,), dtype=float32),
dense_shape=tf.Tensor([4 4], shape=(2,), dtype=int64)
)
"""
# Dense Tensor
dense_tensor = tf.sparse.to_dense(sparse_tensor)
print(dense_tensor)
"""
【出力結果】
tf.Tensor(
[[0. 0. 0. 0. ]
[0. 0. 1.1 0. ]
[0. 0. 0. 2.2]
[0. 0. 0. 0. ]], shape=(4, 4), dtype=float32)
"""では、コードの解説です。上記サンプルコードで作成しているSparseTensorは、先ほど挙げた例のものと同一です。tf.sparse.SparseTensorの部分を見ると、indicesという引数で[行・列]のインデックスを保持したリストを渡しており、valuesという引数でそのインデックスに格納されている値を渡していることが分かるかと思います。最後に、dense_shapeという引数で、このSparseTensorの形状を指定しています。
また、後ほど学習のタイミングで必要になりますが、SparseTensorを密なTensor(通常のTensor)に戻す方法もあります。これはtf.sparse.to_dense() という関数にSparseTensorを渡すだけでOKです。上記のサンプルコードを見ると、作成されたSparseTensorが通常のTensorに戻されており、ほとんどの要素の値が0となっていることが分かるかと思います。
SparseTensorをTFRecords形式で保存する方法
次に、SparseTensorをTFRecords形式で保存する方法・その注意点について述べていきます。
前章で見たように、SparseTensorは値を保持している行・列 (axis)の情報と、その値の情報を保持しているため、これをシリアライズするためには以下のようにする必要があります。
- 行のインデックスをまとめたリストを用意し、シリアライズ
- 列のインデックスをまとめたリストを用意し、シリアライズ
- 値を要素に持つリストを用意し、シリアライズ
もちろん、各リストの同じ位置の要素は互いに対応付いているようにしなければなりません。では、具体例で見てみましょう。
import numpy as np
import tensorflow as tf
import scipy
def feature_float_list(l):
return tf.train.Feature(float_list=tf.train.FloatList(value=l))
def feature_int64_list(l):
return tf.train.Feature(int64_list=tf.train.Int64List(value=l))
# Protocol Buffersの形式に変換
# ⇒ あとで3階テンソルとして扱う必要があるので、"channels"の要素も用意
def sp_tensor2example(sp_array, label):
return tf.train.Example(features=tf.train.Features(feature={
"rows": feature_int64_list(sp_array.row),
"cols": feature_int64_list(sp_array.col),
"channels": feature_int64_list(np.zeros(len(sp_array.row)).astype(int)),
"values": feature_float_list(sp_array.data),
"label": feature_float_list([label])
}))
filepath = "./sequence_conv.tfrecords"
# 疎行列・正解データを10個ずつ作成
sp_array_list = [scipy.sparse.random(12, 12, density=0.1) for i in range(10)]
label_list = np.random.rand(10)
# TFRecords形式で保存
with tf.io.TFRecordWriter(filepath) as writer:
for sp_array, label in zip(sp_array_list, label_list):
example_proto = sp_tensor2example(sp_array, label)
writer.write(example_proto.SerializeToString())今回は画像を想定して行列の要素を用意します。疎行列はscipy.sparse の random関数を用いて12×12のランダム行列を作成しました。sp_tensor2exampleの中で定義しているProtocol Buffersの定義に、”rows”, “cols”, “channels”の要素があることに注意してください。このように分けているのは、読み出しの際に区別する必要があるからですね。注意する点はこれだけで、あとは通常通りに作成したExampleをSerializeToString() メソッドでシリアライズしてTFRecords形式に書き出せばOKです。
TFRecords形式で保存したSparseTensorを読み出す方法
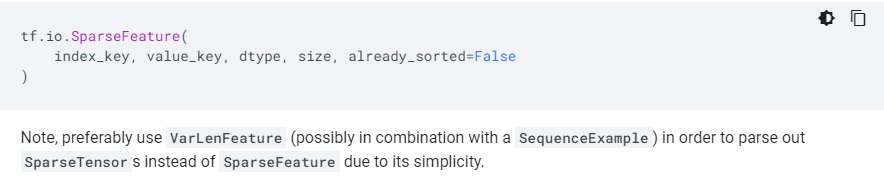
次は読み出しについてです。SparseTensorを直接読み出す際にはtf.io.SparseFeature というクラスを利用します。これはコードを見た方が早いと思いますので、早速サンプルコードです。
import numpy as np
import tensorflow as tf
# 保存しているSparseTensorの形状 ※ Conv2Dでは3階テンソルを要求されるのでこの形状
sparse_shape = [12, 12, 1]
# デシリアライズ用コールバック関数
def parse_example(example):
features = {"train": tf.io.SparseFeature(index_key=["rows", "cols", "channels"],
value_key="values",
dtype=tf.float32,
size=sparse_shape),
"label": tf.io.FixedLenFeature([], dtype=tf.float32)
}
train_data = tf.io.parse_single_example(example, features=features)
x = train_data["train"]
y = train_data["label"]
return x, y
# メイン
filepath = "./sequence_conv.tfrecords"
# TFRecords読み出し & デシリアライズ
dataset_train = tf.data.TFRecordDataset([filepath]).map(parse_example)
for train_X, train_y in dataset_train:
print(train_X)
print(train_y)
"""
【出力結果(長いので一部だけ)】
SparseTensor(
indices=tf.Tensor(
[[ 0 0 0]
[ 0 3 0]
[ 0 6 0]
[ 1 7 0]
[ 2 9 0]
[ 3 3 0]
[ 3 8 0]
[ 4 11 0]
[ 6 6 0]
[ 6 8 0]
[ 8 8 0]
[ 8 10 0]
[11 2 0]
[11 10 0]], shape=(14, 3), dtype=int64),
values=tf.Tensor(
[0.7976593 0.61596143 0.8332581 0.83961755 0.69140923 0.5217606
0.18110311 0.98035353 0.11858348 0.97409976 0.67042786 0.7941748
0.27434942 0.6197932 ], shape=(14,), dtype=float32),
dense_shape=tf.Tensor([12 12 1], shape=(3,), dtype=int64)
)
tf.Tensor(0.4406326, shape=(), dtype=float32)
"""関数parse_exampleの中を見ると、”train”の要素として、tf.io.SparseFeature を指定していることが分かるかと思います。通常のデータの場合は、tf.io.FixedLenFeature か tf.io.VarLenFeature を指定することになるのですが、直接SparseTensorを復元する場合にはtf.io.SparseFeatureを用いるということですね。
引数は全部で4つあります。まず、index_keysには、SparseTensorのうち、値の入っている場所のインデックスがどのラベルのFeatureに対応しているかをリストにして渡します。なお、テンソルの階数分ここにはラベルが必要なことに注意してください(上記の例では、3階テンソルを扱っているので、3つのラベルをリストにして渡しています)。次にvalue_keyにはSparseTensorに入る値のリストがどのラベルかを指定します。dtypeには値の型を、sizeには復元するSparseTensorのshapeを渡します。
※ SparseFeatureについて、公式ホームページによると「tf.VarLenFeature と tf.train.SequenceExample の組み合わせでやった方がシンプルだからベターやで!」とのことです。しかし、両方とも公式サイトにほぼ情報がないので、やり方がイマイチ分かっていません。後日分かったら追記か別の記事で紹介します。
さて、ここまででSparseTensorをTFRecordsから直接復元するための方法を見てきました。最後に、復元したSparseTensorをモデルに直接入力して、学習を行う方法について記載します。
SparseTensorをモデルに直接入力して学習を行う方法
いよいよ学習です。SparseTensorを直接モデルに入力すると、学習実行時にエラーとなります。ということでいくつか対応が必要になります。長ったらしく書くのもアレなので、先に必要な処理を列挙しておきます(Keras APIを使用することを前提にしています)。
- tf.keras.layers.Input の引数で sparse=True を指定する
- tf.keras.layers.Input の引数で batch_size を陽に指定する
- Inputの層に次に、tf.keras.layers.Lambdaを用意し、tf.sparse.to_denseを作用させる
結論から言うとこの3つです。一つ目はオプションにあるので何となく察しがつく内容です。しかし、それだけでは
ValueError: The last dimension of the inputs to Dense should be defined. Found None.
のようなエラーが出て学習ができません。これの解決策が2つ目になります。どうやら、keras APIの内部で sparse_placeholder を使用しているようなのですが、バッチサイズの指定がないときにこれが悪さをするということらしいです(詳細は未検証)。
3つ目は、内部的に密なTensorに戻してあげる必要があるので、それを指定するということですね。
参考にしたgithubのissueを掲載しておきます。
では、実際の学習コードを見ていきましょう。今回は例として畳み込み層を使用したものを作りました(SparseTensorの階数を維持して入力したかったため)。
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Flatten, Lambda, Conv2D
from tensorflow.keras.optimizers import RMSprop
# 保存しているSparseTensorの形状 ※ Conv2Dでは3階テンソルを要求されるのでこの形状
sparse_shape = [12, 12, 1]
# 各種パラメータ
DATA_SIZE = 10
batch_size = 2
steps_per_epoch = (DATA_SIZE-1) // batch_size + 1
kernel_size = (4, 4)
num_filters = 4
# デシリアライズ用コールバック関数
def parse_example(example):
features = {"train": tf.io.SparseFeature(index_key=["rows", "cols", "channels"],
value_key="values",
dtype=tf.float32,
size=sparse_shape),
"label": tf.io.FixedLenFeature([], dtype=tf.float32)
}
train_data = tf.io.parse_single_example(example, features=features)
x = train_data["train"]
y = train_data["label"]
return x, y
# メイン
if __name__ == "__main__":
# TFRecordsファイルへのパス
filepath = "./sequence_conv.tfrecords"
# TFRecordsファイルの読み出し ※学習用に、バッチサイズと繰り返し回数を指定
dataset_train = tf.data.TFRecordDataset([filepath]) \
.map(parse_example) \
.batch(batch_size) \
.repeat(-1)
# Keras API でのモデル構築
inputs = Input(batch_size=batch_size, shape=sparse_shape, sparse=True)
X = Lambda(tf.sparse.to_dense)(inputs)
X = Conv2D(filters=num_filters, kernel_size=kernel_size)(X)
X = Flatten()(X)
X = Dense(1, activation="relu")(X)
model = Model(inputs, X)
model.compile(
loss="MSE",
optimizer=RMSprop()
)
print(model.summary())
# 学習実行
model.fit(
x=dataset_train,
epochs=3,
verbose=1,
steps_per_epoch=steps_per_epoch
)
"""
【出力結果】
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(2, 12, 12, 1)] 0
_________________________________________________________________
lambda (Lambda) (2, 12, 12, 1) 0
_________________________________________________________________
conv2d (Conv2D) (2, 9, 9, 4) 68
_________________________________________________________________
flatten (Flatten) (2, 324) 0
_________________________________________________________________
dense (Dense) (2, 1) 325
=================================================================
Total params: 393
Trainable params: 393
Non-trainable params: 0
_________________________________________________________________
None
Train for 5 steps
Epoch 1/3
5/5 [==============================] - 0s 90ms/step - loss: 0.1210
Epoch 2/3
5/5 [==============================] - 0s 3ms/step - loss: 0.1038
Epoch 3/3
5/5 [==============================] - 0s 2ms/step - loss: 0.0836
"""問題なく動作していることが分かるかと思います。
まとめ
本記事では、SparseTensorの扱いについて以下の点を見ていきました。
- SparseTensorの作成・Tensorへの変換方法
- SparseTensorをTFRecords形式に保存・そこから読み出して復元する方法
- SparseTensorを用いた学習の実行方法と注意点
本記事を一通り見て、コードを動かすことでSparseTensorの扱いについては何となくわかるようになるはずです。なお、本文中でも言及しましたが、tf.io.SparseFeature は公式が推奨するものではないので、可能なら後日推奨する方法での記述についても言及したいと考えています。
では、今回は以上となります。最後までお読みいただき、ありがとうございました!

コメント