こんにちは、novです。
今回はヒープソートの原理とその実装について解説していきます。
基本情報や応用情報の勉強をしていると、必ず目にするのがソートアルゴリズムです。そのうち時間計算量が \( O(Nlog(N)) \) であるものとして「ヒープソート」があります。同じ計算量(厳密には異なりますが)のアルゴリズムとしては「クイックソート」「マージソート」などがありますが、ヒープソートはこの二つより比較的理解しにくいものではないかと思います。
理由としては、ヒープソートの理解には
の2段階を経る必要があるためだと個人的に考えています。前者の「ヒープ」が理解できてしまえばそれほど難しい話ではないのも特徴です。
また、実装に際しては「1次元ヒープ」という考え方も知っておく必要があります。
この記事では、ヒープというデータ構造について具体例を交えながら解説し、その後ヒープソートの解説・実装例の紹介を行います。
上記で挙げたキーワードを初心者でも分かるように説明するのでぜひ最後までお読みください♪
目次
ヒープとは何か?
ヒープ(Heap)とは、「塊」を意味する英単語です。IT系の文脈において、ヒープは次の2つの意味を持ちます。
前者がヒープソートに関わる「ヒープ」です。優先度付きキューについては次節で説明しますが、ざっくりいうと
「常に最大(または常に最小)の要素が返されるキュー」
と捉えておくと良いです。キューについては、現時点では適当な配列をイメージしておけばOKです。
例えば、{2,5,3,7}という優先度付きキューがあったとき、要素を取り出す作業(=dequeue)を行うと、「7」が取り出され、残りのキューは{2,5,3}となります。
残ったキューに対して再度dequeueを行うと、5が取り出され{2,3}が残る…という動作イメージになります。
後者の「ヒープ」はC言語でいうところの「malloc」などを使用したとき、動的にメモリ確保を行うための領域を指します。
この記事では詳しく説明しないので、気になる方は以下のサイトなどを参照してください。このブログでも後日解説をしようと思います。

以上が概要になります。
では、優先度付きキューからヒープまで更に細かい解説をしていこうと思います。
優先度付きキューとは?
優先度付きキューとは、以下のような操作を持つデータ構造です(Wikipediaより引用)。
重要なのは上二つですね。優先度付きキューは抽象データ型の一種なので、これだけではイメージがわきにくいと思います。
ということで、最低限必要となる上二つの性質について具体例を用いて解説してみます。
まずは、一つ目の「要素を優先度付きで追加する」についてです。イメージは下記の図です。
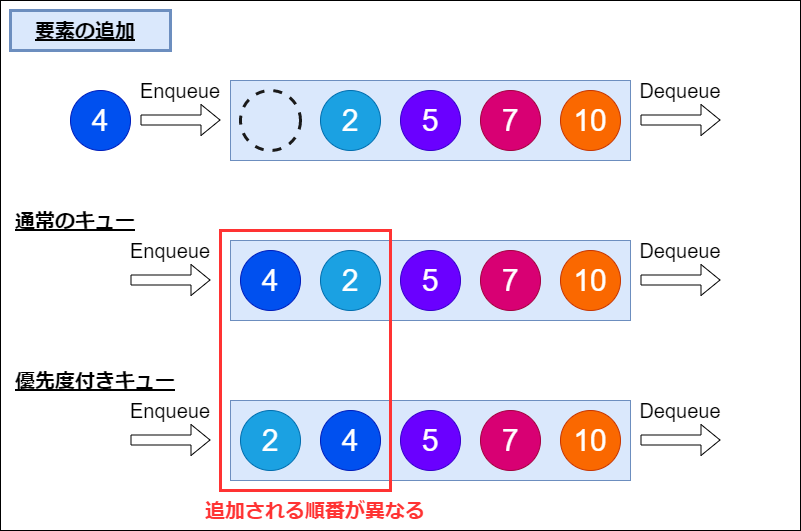
通常のキューは新しく追加された要素が最後に追加されますが、優先度付きキューでは優先度に応じて追加される位置が変化します。
上記の図では、「優先度4」の要素が追加されていますが、優先度付きキューではそれが最後ではなく、優先度2と優先度5の要素の間に挿入されていることがわかるかと思います。
余談ですが、何かしらの優先度の情報を保持してキューを作れば「キューに対して要素を優先度付きで追加する」は満たされます。したがって、このイメージ図は「優先度付きキュー」の一例に過ぎない点に注意してください。
次に、二つ目の「最も高い優先度を持つ要素をキューから取り除き、それを返す」についてです。これもイメージは下記の図です。
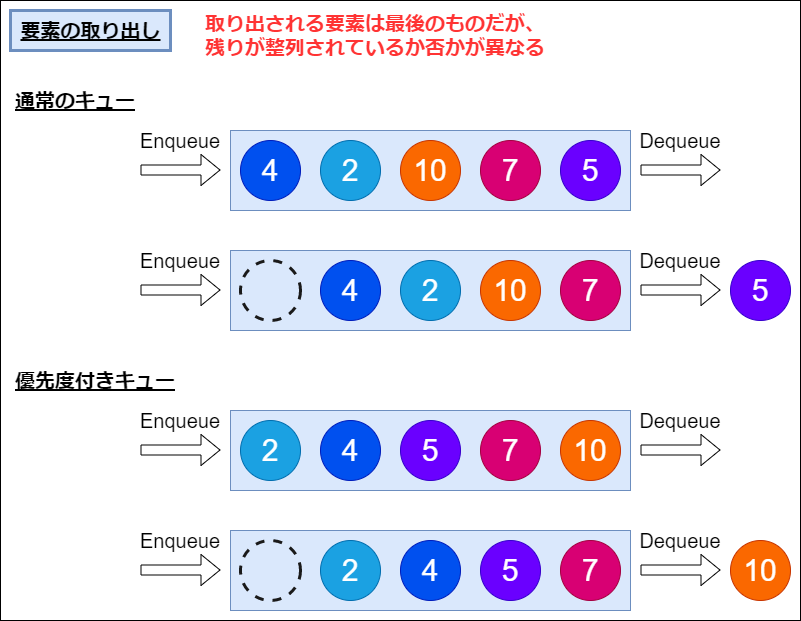
通常のキューからの取り出し操作は、一番最後の要素を機械的に取り出すというものであり、優先度付きキューの取り出し操作は一番優先度の高いものを取り出すというものです。
図の中では、優先度付きキューの並びを整列したものにしていますが、定義上は整列されている必要はありません。最大の要素が取り出せればOKです。
つまり、以下のような形でもOKということです。
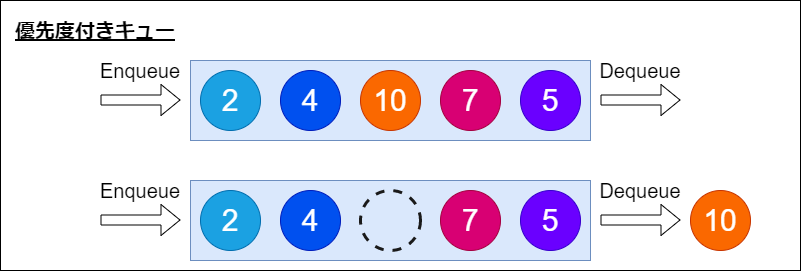
優先度付きキューの概要については以上です。
なお、ソートアルゴリズムと優先度付きキューとの関係についてですが、列挙した性質のうち
「最も高い優先度を持つ要素をキューから取り除き、それを返す」
というものを繰り返し使用すると、キューに含まれていた要素が大きい順に取り出されることになります。
すなわち、ソートアルゴリズムの一部として活用できるということです。
Wikipediaの優先度付きキューの項目にも言及がありますが、
- 選択ソート
- 挿入ソート
- ヒープソート
は、全部優先度付きキューの考え方がアルゴリズムの内部で適用されています。異なるのは優先度付きキューの実現方法だけです。
今回の記事はヒープソートについてなので、次に優先度付きキューの実現方法の一つである「ヒープ」というデータ構造について見ていきます。
「ヒープ」にも種類が色々あるのですが、ここではヒープソートに最低限必要な「二分ヒープ」について解説していきます。
二分ヒープのデータ構造
二分ヒープとは、二分木に以下の制約を追加したものです。
- 木は完全二分木か、完全に分岐の葉を右からいくつか取り除いた形になる
- それぞれのノードは、そのノードの子ノードの値より大きいか、等しい値を持つ
つまり、データの形状としては以下のようなものを想定するということです。
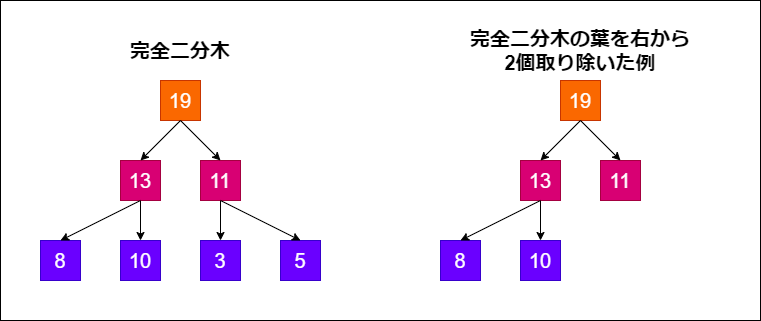
図について解説します。まずは一つ目の条件に関してです。
上図のうち、左側が完全二分木であり、右側が完全二分木の葉を右から2個取り除いた例です。
完全二分木は根から葉までの深さがすべて等しい木のことです。
上図の例では、「19」のノードが「根」であり、「8,10,3,5」のノードが「葉」に対応します。また、根から葉までの深さはすべて「2」なので、完全二分木の条件を満たしています。
次に二つ目の条件について解説します。
上図の左側について見ると、根とその子ノードについて
- 19 > 13
- 19 > 11
が成り立っており、葉ノードとその親ノードについて
- 13 > 8
- 13 > 10
- 11 > 3
- 11 > 5
という大小関係が成り立っています。このように、「親ノード \( \ge \) 子ノード」という関係が木全体で成り立つことがヒープの条件です。
なお、今回は数値の大小関係で説明しましたが、比較演算子が定義できるものなら同様に考えてヒープを構成することができます(文字列など)。
さて、ここまでが二分ヒープのデータ構造についての説明です。
次に、二分ヒープから最大の要素を抽出した後の「ヒープ再構成」の手順について述べます。
ヒープの再構成
ヒープは「優先度付きキュー」の一種なので、「最大の要素を取り除き、それを返す」という操作を持ちます。
しかし、二分ヒープの最大の要素を取り除くと、下図のように木が二つに分かれてしまいます。
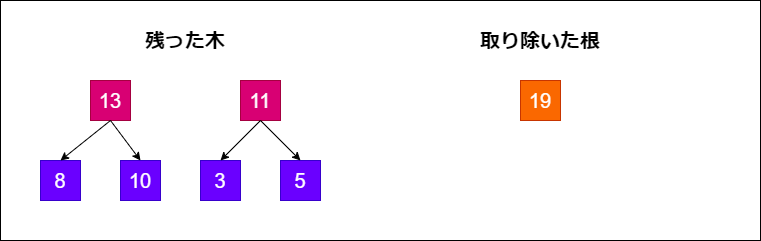
そこで、残った要素で再度ヒープを再構成する必要があります。
再構成のやり方は、以下の手順になります。
- 残った木のうち、もとの二分ヒープで一番右側にあったノードを根に配置する
- 根と子ノードの値を比較し、子ノードの大きい方の値よりも根の値が小さければそれを交換する
- 入れ替えた先のノードを親ノードとし、その子ノードの値を比較、子ノードの大きい方の値よりも親ノードの値が小さければそれを交換する
- 3.の手順を交換が必要なくなるまで繰り返す
以下、上図の状況を例に、手順を図示して説明します。
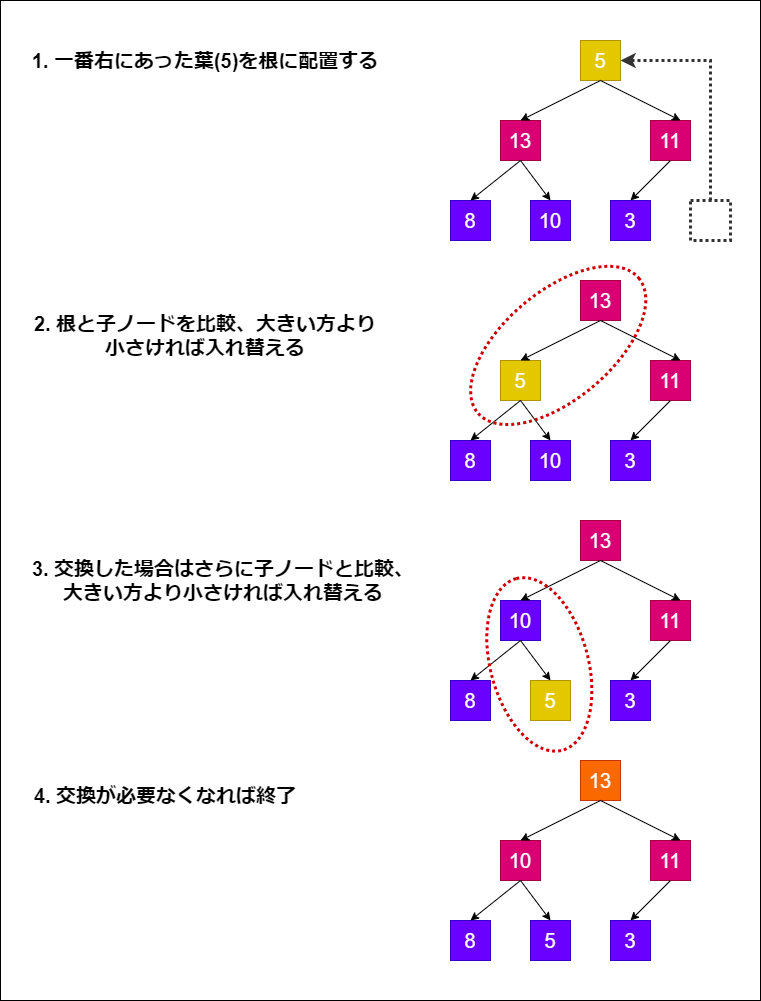
まず、1つ目の処理について、一番右側にあった葉ノード「5」を根に配置します。
2番目の処理では、根に配置されたノード「5」と、その子ノード「13, 11」と大小を比較します。
ヒープは最大の要素が根に来るので、子ノードのうち大きい方と値を比較します。今回は「5」と「13」を比較することになります。
13の方が大きいので、5と13のノードを入れ替えます。
3番目の処理では、「5」のノードとその子ノード「8, 10」との大小を比較します。
大きい方の要素「10」と比較した結果、「5」よりも大きいので入れ替えます。
最後に、葉まで交換が終わるか、途中で交換の必要がなくなれば処理を終了します。
これが二分ヒープの再構成処理です。
なお、上記の例では、元の要素数が7に対し、入れ替えの処理が最大で2回ということが分かるかと思います。
二分木は、要素数\( N \)に対してその最大の深さが \( logN \)となるため、入れ替えの回数がせいぜい\( logN \)で抑えられることになります。
ここまで二分ヒープのデータ構造について見てきましたが、これはグラフ構造であるため、このまま実装すると「ノード」を構造体として準備する必要が出てきます。
具体的には
- 自身の優先度を保持する変数
- 子となるノードへのポインタ1
- 子となるノードへのポインタ2
のデータを保持する必要があります。これではややメモリ効率が悪いため、配列で二分ヒープを構成することを考えます。
これを1次元二分ヒープと呼びます。以下、その構成方法について述べます。
1次元二分ヒープの構成
1次元2分ヒープは、以下のような性質を持つ配列です。
- 配列の値が優先度に対応する
- i番目の要素は、2i番目、2i+1番目の要素を子ノードとする
要は、二分ヒープの要素を根から浅い順に配列の要素に配置するというものです。
前節で説明したヒープ構造を1次元ヒープに置き換えると以下のようになります。
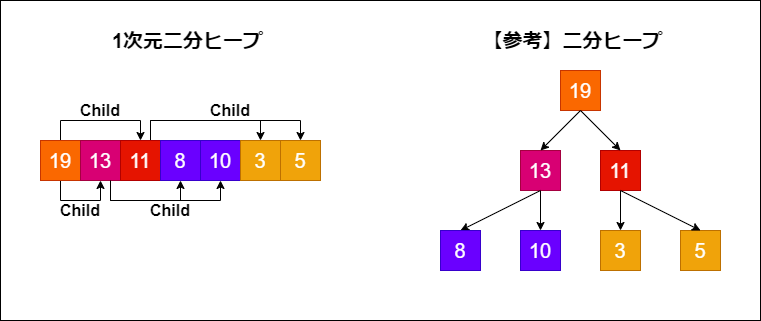
こうすることで、N個の要素を格納する二分ヒープは長さNの配列と同様のメモリ領域で表現することが可能となります。
以上でヒープソートに必要となる「ヒープ」の解説は終わりです。
ヒープソートのアルゴリズム
ヒープに関する解説が終わったのでヒープソートそのものの解説に入ります。
ヒープソートは、計算時間が \( NlogN \)であるような不安定な内部ソートです。
内部ソートなので、配列そのもの以外に追加で確保するべきメモリ領域がほとんどないということになります。
以下、アルゴリズムの手順を述べます。
- ソート対象の配列を1次元二分ヒープとなるように並べ替え、カウンタiの値を1にセットする
- 一番左の要素を、一番右の要素と入れ替える(最大の要素抽出と、葉の一番右の要素を根に配置する操作に対応)
- 配列の左側N-i個の要素で1次元二分ヒープを再構成する
- 一番左の要素を、N-i番目の要素と入れ替え、カウンタiに1を加える
- 以下、3,4の操作をi=Nとなるまで繰り返す
要は、配列の左側の領域を未ソートの要素からなる「1次元2分ヒープ」を表す部分とし、右側の領域をソート済みの配列を格納する場所として用いるということですね。
これが分かれば実装は比較的容易です。あとは実装する言語に合わせてインデックスの付け方が変化するくらいです。
では最後にC++での実装例を見ていきましょう!
ヒープソートのC++実装例
以下にヒープソートのC++実装例を示します。
ヒープソートのアルゴリズムのうち、3番目の処理の実装については、「親ノードとなりうるインデックス」に至るまで処理を繰り返すということを念頭に入れると理解しやすいと思われます。
分かりづらければ、2分ヒープの木構造に、配列のインデックスに対応した番号を振ってみるとイメージがつかめると思います。
#include <iostream>
template <typename T>
void swap(T &a, T &b)
{
T c;
c = a;
a = b;
b = c;
}
// ヒープ構成処理
template <typename T>
void CreateHeap(T *array, int n)
{
while (n > 0)
{
int i = (n - 1) / 2;
// 親ノードの値の方が小さいとき、入れ替え → 根ノードの値が最大値になるよう構成する
if (array[n] > array[i])
{
swap(array[n], array[i]);
}
n = i;
}
}
template <typename T>
T PopHeap(T *array, int n)
{
// 最大値取得(根の要素)
T max = array[0];
// 以下ヒープ再構成の処理
array[0] = array[n]; // 2分ヒープの最後の要素を根に配置する
// 親ノードとなり得る最大のインデックスに到達するまで処理を繰り返す
int parent_idx = 0;
int child_idx;
// ヒープ再構成部分の要素数はn-1。0スタートのインデックスなので、親と子のインデックスの関係は c_id = p_id * 2 + 1 or p_id * 2 + 2
// したがって、int((c_id_max+1) / 2) が親ノードの最大値。c_id_max = n-1なので、以下の式が条件になる
while (parent_idx < n / 2)
{
// 子ノードの左側インデックス算出
child_idx = 2 * parent_idx + 1;
// 左右の子ノードのうち、値の大きいもののインデックスをchild_idxとする
if (array[child_idx] < array[child_idx + 1])
{
child_idx++;
}
if (array[parent_idx] < array[child_idx])
{
swap<T>(array[parent_idx], array[child_idx]);
}
parent_idx = child_idx; // 入れ替え候補となったノードのインデックスを親ノードのインデックスとする
}
return max;
}
template <typename T>
void HeapSort(T *array, int N)
{
for (int i = 1; i < N; i++)
{
CreateHeap<T>(array, i);
}
for (int i = N - 1; i > 0; i--)
{
array[i] = PopHeap(array, i);
// PopHeapに渡しているのは、ヒープにする要素の数(i番目の要素以降はソート済みの部分になる)
}
}
// 動作確認
int main(){
using std::cout;
using std::endl;
// int型で検証
int array[] = {4, 13, 2, 56, 7, 84, 0, 7, 9, 1};
int N = int(sizeof(array) / sizeof(array[0]));
for (int i = 0; i < N; i++)
{
cout << array[i] << " ";
}
cout << endl;
// ソート実行
HeapSort<int>(array, N);
cout << "--- Array Sorted ---" << endl;
for (int i = 0; i < N; i++)
{
cout << array[i] << " ";
}
cout << endl;
return 0;
}
/* 実行結果
4 13 2 56 7 84 0 7 9 1
--- Array Sorted ---
0 1 2 4 7 7 9 13 56 84
*/
まとめ
今回は「優先度付きキュー」の概念からスタートし、ヒープについて説明し、最後にヒープソートのC++実装例を紹介しました。
エンジニアとしては実装そのものを知っておくことは当然重要ですが、それ以上に抽象データ型である「優先度付きキュー」について理解し、その実現方法について幾つかの方法を知っておくことの方が応用上重要ではないかと思います。
この記事を順番に見ていけばヒープソートについてかなり理解できると思います。
よくわからず困っている人の助けになれば幸いです。


コメント