
そうだ、SageMakerで分散学習をやってみよう
こんにちは、novです。
今回の記事では、AWSの機械学習マネージドサービスの一つである
SageMaker
を用いて、分散学習を行う際にハマった部分をメモしていこうと思います。
ちなみに背景は以下です。
- 仕事でDeep Learningを用いた軌道予測の技術開発をしている
- モデルが重量級だった&訓練データの数が多かったので単一GPUだと学習に鬼時間がかかる
- 仮説検証のサイクルは速く回したいので、費用が嵩んででも高速で学習したい
- 複数GPUを積んだインスタンスを複数使用し、高速に計算を回そう!
- あれ、公式ブログにあるようにhorovodのコード書いたのにトレーニングジョブが分散学習になってないぞ…?
- 英語で探しても情報落ちてねえじゃねえか!しゃーない、サポートに聞こう。
- 無料プランじゃ分からんって何だよ!仕方ねえ、課金して有料プランで聞くか…
- 直ぐ分かりませんでした。地味に1週間ほど経ってから回答されましたとさ。
てなわけで、解決にひと月くらいかかったんですよね。
ここの使い方とかでハマって時間とお金を無駄にする日本企業とかあるとなかなか目も当てられない気がするので、頭に入っている内容くらいは共有しようということです。
ちなみに自分がハマった理由は、SageMakerのノートブックインスタンスにデフォルトで入っている SageMaker Python SDKのバージョンがhorovodでの分散学習に対応していないことでした。
要は以下のコマンドを、ノートブックインスタンス上のJupyter Notebookで実行しろという話です。
!pip install --upgrade sagemakerどうやらSageMaker SDKのバージョンが2.18.0以上でないとダメな模様。
いやそんなんドキュメントに書いてないから分かんねえよ….
はい、ということで恐らくハマるであろう内容は以上ですね。
ただ、これで終わるの味気ないので、horovodの仕組み・出てくる用語について本文でザックリまとめようと思います。
horovodって何ぞ?
Tensorflow(Keras), PyTorch, Apache MXNetを使用した学習において、分散学習の簡単なAPIを提供するOSSフレームワークです。
詳細は以下の公式ドキュメントを参照いただければと思います(英語ですが…)。

インストール方法については、リンク先の「Get started」の項目に記載があるのでそちらに詳細は譲ります。AWS SageMaker上でしか試していないので、ローカルで構築できる保証がないのは内緒です☆
これだけではイマイチピンとこないかもしれないので、Keras(Tensorflow2系のAPI)での書き方を見ながら、どういう挙動をしているのかざっくり説明してみましょう。
horovodの挙動とサンプルコード
では早速サンプルコードを交えてイメージを見ていきましょう。
サンプルコードは以下から拝借してきました。

import tensorflow as tf
import horovod.tensorflow.keras as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if gpus:
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
# Build model and dataset
dataset = ...
model = ...
opt = tf.optimizers.Adam(0.001 * hvd.size())
# Horovod: add Horovod DistributedOptimizer.
opt = hvd.DistributedOptimizer(opt)
# Horovod: Specify `experimental_run_tf_function=False` to ensure TensorFlow
# uses hvd.DistributedOptimizer() to compute gradients.
mnist_model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),
optimizer=opt,
metrics=['accuracy'],
experimental_run_tf_function=False)
callbacks = [
# Horovod: broadcast initial variable states from rank 0 to all other processes.
# This is necessary to ensure consistent initialization of all workers when
# training is started with random weights or restored from a checkpoint.
hvd.callbacks.BroadcastGlobalVariablesCallback(0),
]
# Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them.
if hvd.rank() == 0:
callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch}.h5'))
model.fit(dataset,
steps_per_epoch=500 // hvd.size(),
callbacks=callbacks,
epochs=24,
verbose=1 if hvd.rank() == 0 else 0)サンプルコードに書かれている内容のうち、horovod特有の内容を列挙すると以下のようになります。
- hvd.init()をコールする(初期化処理)
- hvd.local_rank()を使用し、並列動作させるプロセスに、どのGPUを紐づけるかを明示する
- optimizerのインスタンスを、hvd.DistributedOptimizer()でラッピングする
- hvd.rank()が0のプロセスについてのみ、そこで計算された重みをチェックポイントに記録するよう設定
- model.fit()の引数に、callbackとして、hvd.callbacks.BroadcastGlobalVariablesCallbacks(0)の格納したリストを渡す
- 1エポックあたりのstep数は、並列プロセス数で割る(hvd.size()で取得)
いくつか補足がないと理解不能な概念があるので説明します。以下は概要図です。
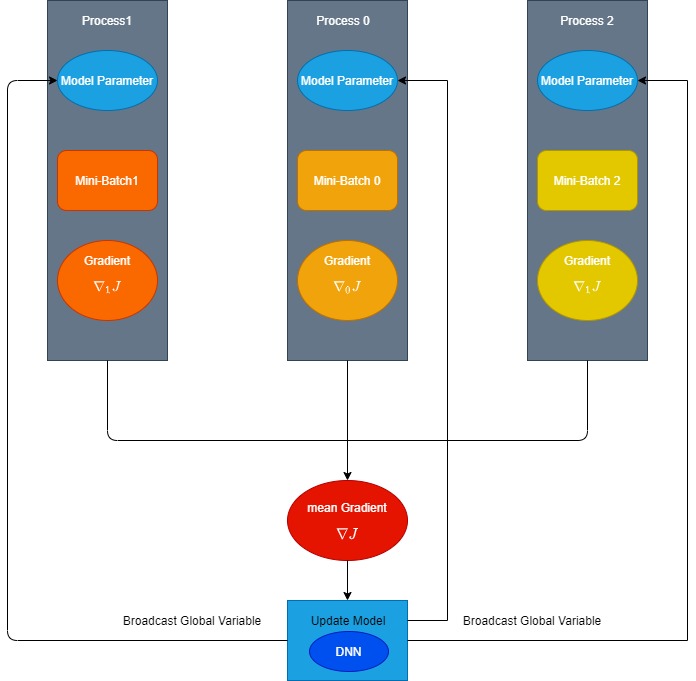
まず、horovodは分散学習用のフレームワークなので、当然ながら複数のプロセスを走らせることを前提にしています。
そして、上記のサンプルコードはこの「並列に動作するプロセス」一つ一つで動作するコードになります。
分散学習においては、ミニバッチを複数のプロセスにそれぞれ割り当てて計算したのち、各プロセスで計算した勾配を平均してパラメータを更新します。
この際、親となるプロセスの重みを更新し、残りのプロセスにその重みを共有する必要が出てくるわけです。
そのためには各プロセスが
「自分が親か否か、そもそもどのプロセスなのか?」
ということを識別できる必要があります。
そこで登場するのが”rank”という概念です。基本的に、親となるプロセスに0というrankが割り当てられます。
また、”local_rank”と”rank”の2種類が存在する理由についてですが、これは物理的なマシンが複数ある場合に意味を持ちます。
rankは全体のプロセス一つ一つで異なる番号が割り当てられており、local_rankは一つのマシン内で並列に走るプロセス一つ一つにつけられた番号ということになります。
例えば、GPUを4つ積んだマシンを2台使用し、8つのプロセスを並列に動作させる場合を考えます。
この場合、rankには0から7の番号が割り当てられており、local_rankはそれぞれのマシン内のプロセスに、0から3の番号が割り当てられていることになります。
図にすると以下のようなイメージですね。
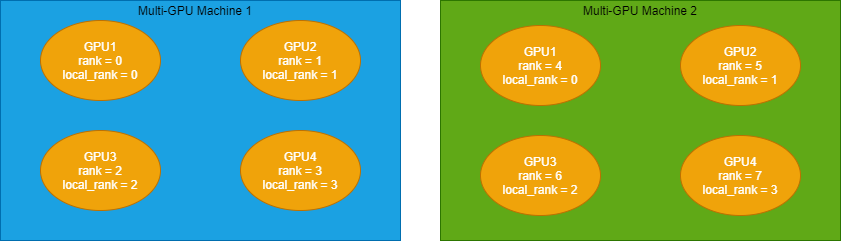
あくまでイメージなので、実際の番号の割り振りはこの通りとは限りません。rankの最大値とlocal_rankの最大値が異なることだけ分かればOKです。
と、このように各プロセスはhvd.rankで区別し、その数値に合わせてGPUの指定を行い、rank==0のプロセスで計算した重みを全体に共有(=Broadcast)しているという訳です。
意味さえ分かってしまえば何ということはありませんね。
まあここについて細かく説明している資料がなかなか見つからなかった訳ですが…
では、最後にhorovodを利用して分散学習を行う際のコマンドに触れて終わりにしたいと思います。
horovodを利用して分散学習を行う際のコマンド
公式ドキュメントにあるコマンドを例に説明します。
horovodrun -np 4 -H localhost:4 python train.py早速それぞれの意味について説明していきます。
- horovodrun:horovodを使用して並列にプロセスを起動するコマンド
- -np 4:おそらく 「Number of Processes」の略。このコマンドで起動するプロセスの数。
- -H localhost:4 : どのサーバーで起動するかの設定。この例では、コマンドを実行するホスト上で起動する設定
- python train.py:horovodで並列実行する学習用スクリプト。pythonも呼び出す点に注意。
割と直感的ですね。実は、horovodrunの裏側では「mpirun」が走っています。
つまり、horovodは、OpenMPIを使用しているということです。
mpirunで指定するべきパラメータは多数あるのですが、分散学習をするにあたって必要なパラメータは限られているので、horovodでは必要なパラメータだけを指定すれば後は適切なパラメータでmpirunを起動してくれるという訳ですね。
OpenMPIについてはかなり細かくコマンドライン引数がある上、筆者がそこまで詳しくないので、公式ドキュメントのリンクを貼るだけでお茶を濁しておきます。。。
もしある程度理解が進んだら記事にするかもしれません。

まとめ
今回の記事では、SageMaker上でhorovodを使用して分散学習を行う際の注意点と、horovodそのものについて開設してみました。
主に後者がメインになってしまいましたが、これから分散学習をやりたいけど、専門用語とかが分からん!ってなっている方の助けになれば幸いです。
では以上とします。最後までお読みいただき、ありがとうございました!


コメント