こんにちは、novです。
今回は前回の記事の続きです。

前回はローダ作成に必要なライブラリの使い方をまとめたのでした。
今回は
- MNISTのフォーマット
- 要件と照らし合わせたローダの設計
- 実際のコード
の順に解説しようと思います。
githubにもコードを公開していますので、興味のある方は触ってみてください。
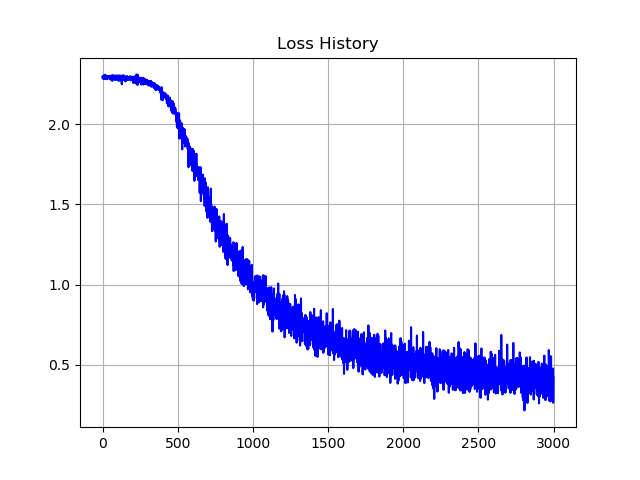
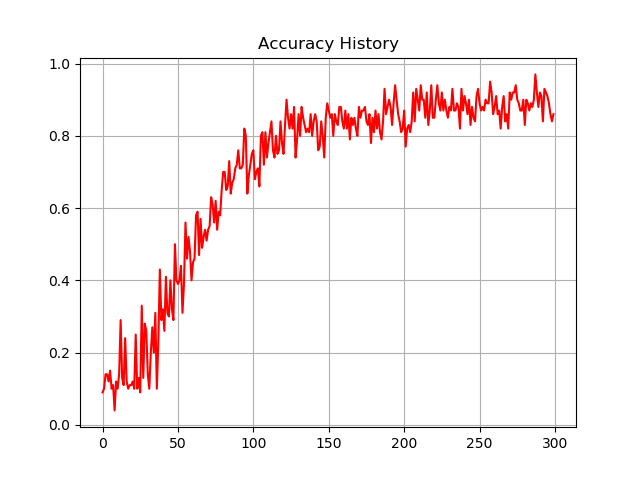
MNIST学習用のサンプルコードも合わせて置いてあります。実行結果で得られる画像の例は以下です。
なお、必要最小限の要件で構成しているので、公開しているものは十分にテストされたコードとは言えない部分があります。
利用は自由ですが、自己責任でよろしくお願いします。
MNISTのフォーマット
様々なサイトで解説されているので、n番煎じ感が否めませんが触れておきます。
後ほどの設計にも影響する部分があるので、やや丁寧に解説します。
MNISTの公式ページには以下のように記述されています

※ 例として訓練データの方だけ抜粋して掲載します
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …….. | …….. | …….. | …….. |
| xxxx | unsigned byte | ?? | label |
The labels values are 0 to 9.
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …….. | …….. | …….. | …….. |
| xxxx | unsigned byte | ?? | pixel |
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
この表の見方ですが、offsetはファイルの先頭から何byte目のデータについてかを示しています。typeはデータの型、valueはその値を示し、descriptionはその数値の意味を記載しています。
この表の内容を図解すると以下のようになります。
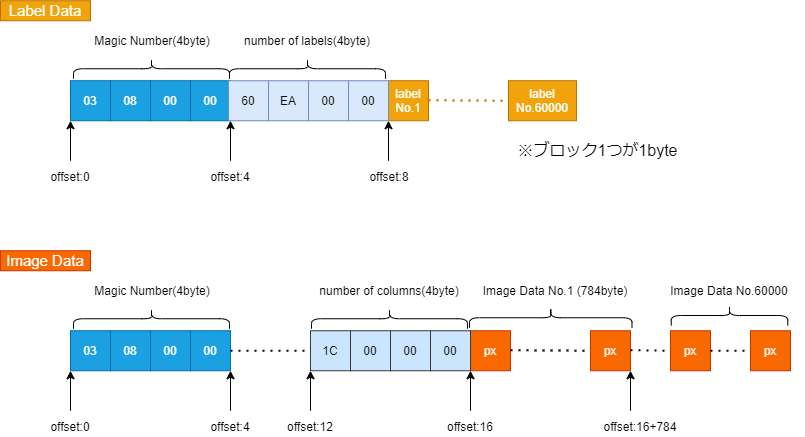
Labelデータの方に関しては、最初の4byteがマジックナンバー(詳細は後述)であり、次の4byteがデータの数になります。それぞれ値としては2049, 60000となります。
その後は1byteずつラベルの値(0~9のいずれか)が入っています。これがデータの数(訓練データの場合は60000)だけ続きます。
Imageデータの方に関しては、16byte目まで順に「マジックナンバー」「データの数」「画像の行数」「画像の列数」が4byteずつ入っています。
それぞれ、値としては2051, 60000, 28, 28になります。
その後、17byte目から画像データが続きます。各ピクセルの値は0~255の範囲なので、8bit=1byteずつ格納されており、それがピクセル数分並んでいます。つまり、1つの画像あたり28×28=784byte分データがあり、それが60000データ分並んでいることになります。
データを読み出す際は、784byteずつ読み出すことになるので注意が必要です。
なお、テストデータの場合はデータの数が10000となります。
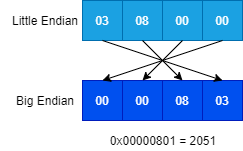
ラベルデータ最初の8byte、画像データ最初の16byteに関しては4byteずつデータが格納されていますが、これはリトルエンディアンで格納されています。
読み出す際には、以下の画像のようにビッグエンディアンに変更してメモリ上に展開してやる必要があります。ここも注意が必要なポイントです。
余談ですが、このデータ形式は「IDX File Format」というもので、以下のような並び順のデータ形式です。
主にベクトル・多次元配列のデータを保存するためのフォーマットとして規定しているようです。

| マジックナンバー(4byte) |
| 1次元目のサイズ |
| 2次元目のサイズ |
| …. |
| N次元目のサイズ |
| データ |
| …. |
マジックナンバーは4バイトデータであり、上位2byteは常に0です。
3byte目のデータは、データ型を表しており、その対応は以下の通りです。
| 3byte目の値 | 対応するデータ型 |
|---|---|
| 0x08 | unsigned int |
| 0x09 | signed int |
| 0x0B | short(2bytes) |
| 0x0C | int(4bytes) |
| 0x0D | float(4bytes) |
| 0x0E | double(4bytes) |
4byte目のデータは、保存されている各データの次元数を表しています。
なお、データはC言語の配列と同様に配置されているため、最後の次元のデータが一番変動することになります。
これを基に、MNISTのマジックナンバーを解釈すると以下のようになります。
- 画像データ : 0x 00 00 08 03 →「unsigned intの3次元配列データ」
- ラベルデータ: 0x 00 00 08 01 →「unsigned intの1次元データ」
なお、今回作成するローダではこのマジックナンバーを内部で解釈して使用するということはしません。
IDX file format一般のローダを作成するときは上記のルールに従って内部で処理を分岐することになるかと思います。
ローダの設計
要件
「ゼロから作るDeep Learning」に記載されているローダと同様の機能を持つよう、また自分が使用する上で使いやすい形になるよう要件を定めました。
- クラスとして実装すること
- バッチサイズを指定できること
next_train()といったメンバ関数を用い、都度データが読み出せること(メモリに全展開しない)- ランダムにデータを読み出せること
- 正解データはone-hot形式、通常のラベル形式の両方に対応していること
- 画像データは、正規化の有無を指定できること
- EigenのMatrixに対し、データを読み込めること
- フォルダ構成は以下のようなものを想定する
dataset/ ┬ include/ – mnist.h・mnist.cpp
└ data/ – (各種データ)
ざっくり上記を要件として実装します。
使い方としては、以下を想定します。
- ローダはインスタンス化して使用。コンストラクタではバッチサイズとランダム読み出しの有無だけ指定する。
- ミニバッチ単位で読み出す。学習時にはfor文内で
next_train()などのメンバ関数を呼び出し、バッチサイズ分ずつ取得する形にする。
設計内容
クラス名
- MnistEigenDataset
メンバ変数(private)
- 訓練・テスト用画像・正解ラベルのデータへのファイルパス格納変数(
std::string×4) - それぞれのファイルをハンドリングするファイルストリーム(
std::ifstream×4) - 読み出すデータの位置を保持する変数(
std::ifstream::pos_type×4) - 読み出しデータの順番(インデックス)を格納する配列(
std::vector<int>×2) - バッチサイズを格納する変数(
int) - バッチ数を格納する変数(
int訓練・テストの2つ) - 訓練データ・テストデータの読み出し回数を保持する変数(
int×2) - MNISTの4byteデータ格納用変数(_number_of_train_data, _number_of_test_data, _rows, _cols)
メンバ関数(private)
_init_train_loader訓練データ読み込みのファイルストリーム初期化処理_init_test_loaderテストデータ読み込みのファイルストリーム初期化処理
メンバ関数(public)
MnistEigenDataset(const int batch_size, bool random_load=true)コンストラクタnext_train(Eigen::MatrixXd&, Eigen::MatrixXd&, bool one_hot_label=false, bool normalize=true)訓練データ読み出しnext_test(Eigen::MatrixXd&, Eigen::MatrixXd&, bool one_hot_label=false, bool normalize=true)テストデータ読み出し
コンストラクタでの処理
主に初期化処理です。ifstreamのインスタンスに関しては、データ位置まで移動・先頭位置の記憶という処理を行う。
- 指定バッチサイズの保存
- バッチ数の計算と保存
_init_train_loader(),_init_test_loader()の呼び出し- 上記初期化関数で作成した内部インデックスのシャッフル処理(random_load = trueの場合のみ)
内部関数_init_train_loader()と_init_test_loader()の処理内容は以下です(ここでは_init_train_loader()の方を例として出します)。
- 訓練用の画像データ、ラベルデータをそれぞれファイルオープン(
std::ifstream使用) - 画像・ラベルデータともに前から順にデータを読み出し、データ格納位置までファイルポインタを進める。読み出した情報は内部変数に格納する。
※画像はmagic_number, number_of_images, rows, colsがそれぞれ4byteずつで格納されているので計16byte分ファイルポインタを移動することになる
※ラベルはmagic_number, number_of_imagesだけが入っているので8byte分のデータ移動となる
※データはリトルエンディアンなので、それをビッグエンディアンに変更する処理も入れる - 進めた先のファイルポインタ位置を記憶する(
std::iostream::tellg()を使用) - 読み出し用のインデックス配列を作成
データ読み出しメンバ関数の処理
訓練データ・テストデータで構成は同じ。訓練データのものだけ示します。
- 画像・ラベルデータの読み出し用にコンテナを用意(
vector<double>) one_hot_labelを有効化するときは、ラベル格納用のMatrixを「バッチサイズ×10」としてゼロ初期化- バッチサイズ分だけデータを読み出す(処理は以下の6段階で実施)
- 読み出すデータのインデックスを取得する。インデックスを格納した配列において「バッチサイズ×呼び出し回数(
_train_load_count)」の位置からバッチサイズ分を取得。
データの最後まで到達し、まだバッチサイズ分読み出しが終わっていない場合は、インデックス配列の最初から必要な分だけインデックスを取得する - 画像データ・ラベルデータの
ifstreamインスタンスにおいて、seekg()メソッドを使用し、コンストラクタで記憶したベース位置へ移動 - その後再度
seekg()を使用し、インデックスに対応した読み出し位置まで移動。画像データは「インデックスの値×784」、ラベルデータは「インデックスの値」のByte数だけ移動する ifstreamのread()メソッドを使用してデータを読み出す- 画像データに関しては、
Eigen::Mapを使用してMatrixXd型に格納する - ラベルデータに関しても同様。
one_hot_label=trueの場合は、該当する位置のデータを1に変更する
normalize=trueの場合には画像データを255で割る処理を行う_train_load_countをインクリメント(読み出し回数記録)- カウンタの値が、バッチ数に等しくなった場合は0にリセットする
作成ローダのコード
I/F
まず最初に、クラスの宣言を載せます。
ファイルの配置は固定してある前提で作成してあるので、ファイルパスは宣言時に指定しています。
githubにはsetterとセット後の初期化処理も追加したコードを公開しています。
また、デフォルトコンストラクタでは何もしない処理を指定することにしています。実際には安全のためにデフォルト値で初期化処理を行うべきだとは思いますが、今回はパスしています。
class MnistEigenDataset
{
private:
// ファイル入力用
string _train_image_filepath = "./datasets/data/train-images.idx3-ubyte";
string _train_label_filepath = "./datasets/data/train-labels.idx1-ubyte";
string _test_image_filepath = "./datasets/data/t10k-images.idx3-ubyte";
string _test_label_filepath = "./datasets/data/t10k-labels.idx1-ubyte";
ifstream _train_image_ifs;
ifstream _train_label_ifs;
ifstream _test_image_ifs;
ifstream _test_label_ifs;
// ファイルシーク:初期位置記憶用
ifstream::pos_type _train_image_pos;
ifstream::pos_type _train_label_pos;
ifstream::pos_type _test_image_pos;
ifstream::pos_type _test_label_pos;
// ファイルシーク用インデックス格納コンテナ
vector<int> _train_indices;
vector<int> _test_indices;
// 内部変数
int _batch_size;
int _train_max_batch_num;
int _test_max_batch_num;
int _train_load_count = 0;
int _test_load_count = 0;
int _number_of_train_data = 0;
int _number_of_test_data = 0;
int _rows = 0;
int _cols = 0;
private:
void _init_train_loader(void);
void _init_test_loader(void);
public:
MnistEigenDataset(){}; // デフォルトコンストラクタ -> 簡単のため未実装
MnistEigenDataset(const int batch_size, bool random_load=true);
void next_train(MatrixXd &, MatrixXd &, bool one_hot_label=false, bool normalize=true);
void next_test(MatrixXd &, MatrixXd &, bool one_hot_label=false, bool normalize=true);
};コンストラクタのコード
まずはコンストラクタと、その内部で呼び出す初期化関数の実装です。
訓練データ読み出し用の初期化関数と、テストデータ読み出し用の初期化関数では処理内容がほとんど同じであるため、ここでは訓練データ読み出し用の初期化関数のみ記載します。
実行時に読み出しがうまくいっていることを確認するため、標準出力にmagic numberを出力するようにしています。
<!-- wp:code -->
<pre class="wp-block-code"><code>// コンストラクタ
MnistEigenDataset::MnistEigenDataset(int batch_size, bool random_load)
{
_batch_size = batch_size;
// ファイル読み込み初期化処理
_init_train_loader();
_init_test_loader();
_train_max_batch_num = (_number_of_train_data + _batch_size - 1) / _batch_size; // 切り上げ
_test_max_batch_num = (_number_of_test_data + _batch_size - 1) / _batch_size;
// ランダム読み出しの設定をしているときはインデックスをシャッフル
if (random_load)
{
std::mt19937_64 get_rand_mt;
std::shuffle(_train_indices.begin(), _train_indices.end(), get_rand_mt);
std::shuffle(_test_indices.begin(), _test_indices.end(), get_rand_mt);
}
}
void MnistEigenDataset::_init_train_loader(void)
{
// 設定したファイルパスに基づいてファイルオープン
_train_image_ifs.open(_train_image_filepath, std::ios::in | std::ios::binary);
_train_label_ifs.open(_train_label_filepath, std::ios::in | std::ios::binary);
int magic_number = 0;
// 適切な位置までファイルポインタ移動
_train_image_ifs.read((char *)&magic_number, sizeof(magic_number)); // sizeof(magic_number) = 4
magic_number = LittleEndian2BigEndian(magic_number);
_train_image_ifs.read((char *)&_number_of_train_data, sizeof(_number_of_train_data));
_number_of_train_data = LittleEndian2BigEndian(_number_of_train_data);
_train_image_ifs.read((char *)&_rows, sizeof(_rows));
_rows = LittleEndian2BigEndian(_rows);
_train_image_ifs.read((char *)&_cols, sizeof(_cols));
_cols = LittleEndian2BigEndian(_cols);
cout << "IMAGE magic number: " << magic_number << endl;
// 適切な位置までファイルポインタ移動
_train_label_ifs.read((char *)&magic_number, sizeof(magic_number));
magic_number = LittleEndian2BigEndian(magic_number);
_train_label_ifs.read((char *)&_number_of_train_data, sizeof(_number_of_train_data));
_number_of_train_data = LittleEndian2BigEndian(_number_of_train_data);
cout << "LABEL magic number: " << magic_number << endl;
// ファイルポインタ:シーク位置の記憶
_train_image_pos = _train_image_ifs.tellg();
_train_label_pos = _train_label_ifs.tellg();
// 読み出しのためのインデックス作成:単なる整数型でOK(int)
for (int i = 0; i < _number_of_train_data; i++)
{
_train_indices.push_back(i);
}
}
// _init_test_loader()についてはほぼ同様なので省略</code></pre>
<!-- /wp:code -->データ読み出しメンバ関数のコード
メインの読み出しコードです。
void MnistEigenDataset::next_train(MatrixXd& train_X, MatrixXd& train_y, bool one_hot_label, bool normalize)
{
// 読み出し用一時変数
int pixels = _rows * _cols;
vector<double> tmp_image(pixels); // 配列のサイズ初期化は必要(でないとセグフォとなる)
vector<double> tmp_labels(_batch_size);
if (one_hot_label){
train_y = MatrixXd::Zero(_batch_size, 10); // one_hot_label有効化時の初期化
}
// インデックス取得:初期位置計算
int start_idx = _batch_size * _train_load_count;
int tmp_idx;
// 訓練データ読み出し メイン処理部
for (int i = 0; i < _batch_size; i++)
{
// 59999を超えたインデックスは0から再カウント
tmp_idx = _train_indices[(start_idx + i) % _number_of_train_data];
// ファイルシーク:画像データのインターバルは「28×28=784byte」あるので注意
// 画像データ
_train_image_ifs.seekg(_train_image_pos); // シークを初期位置に
_train_image_ifs.seekg(tmp_idx * pixels, std::ios_base::cur); // 読み出し位置まで移動
// ラベル
_train_label_ifs.seekg(_train_label_pos); // シークを初期位置に
_train_label_ifs.seekg(tmp_idx, std::ios_base::cur); // 読み出し位置まで移動
// 画像読み出し
for (int j = 0; j < pixels; j++)
{
unsigned char tmp_value;
_train_image_ifs.read((char *)&tmp_value, sizeof(tmp_value));
tmp_image[j] = (double)(tmp_value);
}
// テンプレート実体化のため、コンパイル時に数値指定の必要あり(_rows, _colsが使えない)
train_X.row(i) = Map<Matrix<double, 1, 28*28>>(&(tmp_image[0]));
// ラベル読み出し
unsigned char tmp_label;
_train_label_ifs.read((char *)&tmp_label, sizeof(tmp_label));
tmp_labels[i] = (double)(tmp_label);
// one-hotか否かで場合分け
if (one_hot_label){
train_y(i, int(tmp_label)) = 1;
} else {
train_y.row(i) = Map<Matrix<double, 1, 1>>(&(tmp_labels[i]));
}
}
if (normalize)
{
train_X /= 255;
}
_train_load_count++;
// カウンタリセット → バッチ数とカウントが同じになったら0にする
_train_load_count = _train_load_count % _train_max_batch_num;まとめ
今回はC++にてMNISTデータをEigenのデータ型に合わせて読み込むためのローダの設計・実装例を紹介しました。
実装例では、読み出す値はすべてdouble型としていますが、実際はfloat等で十分と思われます。
更にメモリ効率を上げる場合にはそちらで実装する方が良いでしょう。
また、動作することを最優先にして作成したのもあり、マジックナンバーによるファイルのバリデーションなどは行っていません。
現状Makefileなど用意していませんが、需要があれば準備しようかなと思います。


コメント